Mittwoch, 1. Juni 2011
Jabber/XMPP Präsenz via API
Mittwoch, 4. Mai 2011
Rechnungen mit weiser Vorausschau
Ich habe niemals ein Geheimnis daraus gemacht, dass viele unserer Vorgänge verbesserungswürdig sind. Es wäre auch langweilig und vermutlich auch geschäftsschädigend wenn es nicht so wäre oder ich den Eindruck hätte wir wären schon "Perfekt" - schade wäre es dann auch, denn was sollte man den lieben langen Tag tun, wenn man nicht optimieren oder verbessern könnte? Für Däumchen drehen möchte ich nicht bezahlt werden.
"Bezahlt werden" ist ein gutes Thema! Wir haben bei uns keinen festen Rechnungslauf, sondern stellen Rechnungen so wie es gerade passt. Ich habe schon mehrfach darüber nachgedacht, diesen auf ein festes Datum zu legen, z.B. den 1. oder 14. eines jeden Monats, aber irgendwie missfällt mir das - es war ja immer schon ganz anders.
Die Rechnungsstellung an sich hat so oder so ziemlich viele Faktoren, die sich tweaken lassen. Vor ein paar Jahren konnte war es z.B. möglich, dass Domains sofort in Rechnung gestellt wurden, nachdem sie registriert bzw. in der Buchhaltung vermerkt wurden. War ein bisschen blöd, wenn in relativ kurzen Abständen weitere Domains geordert wurden. Das generiert im ersten Schritt nur unnötig viele Rechnungen, im Nachgang aber auch unnötig viel Arbeit und Kosten. Deshalb schafften wir irgendwann die Möglichkeit Leistungen zu "priorisieren" bzw. so zu flaggen, dass sie nur abgerechnet werden, wenn eine "größere" Leistung wie z.B. Webhosting abgerechnet wurde.
... das funktionierte eigentlich recht gut, nur bildete sich so auch ein "Rückstau" an Leistungen die noch nicht abgerechnet wurden, der im mittleren vierstelligen Bereich lag. Für den Kunden natürlich toll, für uns eher unschön.
Zwischen den Jahren hatten wir daher noch einmal unsere Buchhaltungssoftware verbessert bzw. nachgebessert. So haben wir eine kundenspezifische "untere Grenze" eingeführt, ab der auch solch "nieder Priorisierte" Leistungen abgerechnet werden und z.B. auch das auslaufen des Fiskaljahres berücksichtigt wird und evtl. eine Rechnung erzwungen wird.
Funktionierte super und der Rückstau baute sich kontinuierlich ab (mittlerweile im oberen dreistelligen Bereich)! Bis vor kurzem...
Vor kurzem musste uns dann auffallen, dass ein Kunde in einem recht kurzen Zeitraum relativ viele Rechnungen von uns erhielt. Für das aktuelle Abrechnungsmodell war das absolut in Ordnung, denn der Kunde hatte in kurzen Abständen größere Mengen an Domains bestellt. Ich fand das aber nicht so lustig, den Kunden so häppchenweise mit Rechnungen zu stören, weswegen wir eine Art "Look ahead (and back)" eingeführt haben:
Unsere Buchhaltungssoftware berücksichtigt nun bei der Rechnungsstellung auch, ob in nächster Zeit weitere Leistungen abzurechnen wäre und verhält sich dementsprechend "ruhiger". Auch wenn dadurch kurzzeitig der Cashflow einbrach fühlt sich diese neue Ruhe doch toll an - ich hoffe selbiges gilt für unsere Kunden bzw. besonders diesen einen 
Dienstag, 5. April 2011
PHP-Optimizer APC, eAccelerator und XCache aus Arbeitsspeicher-Sicht
Mittwoch, 23. März 2011
Kein PDF/A
Montag, 21. März 2011
PHP-Update
One-Way-SRS
Okay, das ging schneller als erwartet:
Unser Mailserver kennt nun das Sender Rewriting Scheme (SRS). Theoretisch gilt das für beide Richtungen, also das Umschreiben des Absenders wenn eine E-Mail weitergeleitet wird und das Umschreiben des Empfängers, wenn eine E-Mail an unsere SRS-Domain empfangen wird. Produktiv verfügbar ist aber vorerst nur zweiterer Dienst - der war einfach leichter zu testen und fällt auch eigentlich gar nicht auf, wenn wir den einfach dazu schalten.
Unsinnig eigentlich, denn ohne das shared secret aus unserem E-Mail-System ist es vermutlich niemandem möglich selbst E-Mail-Adressen zu bauen, die von unserem System akzeptiert werden. Vielleicht wollte da jemand einfach nur ein Kreuzchen auf der ToDo-Liste machen.
Dabei ist die andere Richtung viel interessanter und spannender. Wie ich letzte Woche bereits schrieb haben wir für die SRS-Einführung eigenes einen Patch für das von uns eingesetzte Postfix entwickelt. Wie schon dort angedeutet fehlten dementsprechend eigentlich nur noch zwei Dictionaries (bzw. Lookup-Tables). Eigentlich recht trivial, im Zweifel hätte es gereicht zwei Pipes in Richtung libsrs2 zu legen (wenn wir es denn einsetzen würden), aber das wäre nicht sehr "intelligent".
Der bereits erwähnte "Weg zurück", also das Umschreiben des Empfängers einer E-Mail an unsere SRS-Domain, funktioniert genau so. Darf man machen, da der erste Check hier ein Check der Domain ist und die ausschließlich für SRS verwendet wird. Der vorhergehende Schritt, das Umschreiben des Absenders gestalten wir jedoch etwas differenzierter:
- Es werden keine Absender umgeschrieben, die von Domains kommen die ohnehin über unseren Mailserver laufen
- Es werden nur Absender umgeschrieben, die von Domains mit aktivem SPF-Schutz kommen
Kleine persönliche Anmerkung: SRS hat erst einmal nichts mit OpenSRS am Hut. Das sind zwei unterschiedliche Dinge, letztere höre ich mir morgen vermutlich auf den WorldHostingDays im Europa-Park in Rust an
Mittwoch, 16. März 2011
Postfix für Sender-Rewriting-Scheme (SRS) vorbereiten
Das Sender Policy Framework (SPF) ist nun schon fast altes Zeug. Immer mehr Domains verfügen über einen solchen "Schutz" und dementsprechend öfter fallen nun E-Mails auf, die "klassisch" weitergeleitet werden sollten - sei es eine E-Mail die von GMX kommt, ursprünglich an eine bei uns gehostete Domain ging und wieder zurück an GMX geleitet wird - und es nicht funktioniert. Die Problematik ist zwar nahezu überall dokumentiert, aber mitunter doch recht schwer zu kommunizieren.
Das Problem ist bei uns eigentlich auch schon ewig bekannt: Seit 2006 setzen wir auf nahezu allen Domains SPF ein und auch der Lösungsansatz des "Sender Rewriting Scheme" (SRS) war uns ein Begriff. Nur mangelt es bis heute irgendwie an einer passenden Lösung für Postfix (so wie es bei uns zum Einsatz kommt).
Zwar gibt es hier und da ein paar Ansätze oder auch Aussagen a la "Wir haben es geschafft", aber konkrete Angaben bzw. Dokumentation oder etwas öffentlich verfügbares für den Produktiv-Einsatz fehlt gänzlich. In ein paar Foren findet man auch oft die Aussage SRS wäre ein Fall für einen Content-Filter. Letzteres ist sicherlich auch ein einfacher und schneller Weg das "Problem" anzugehen, doch scheint mir der Overhead hier recht enorm zu sein. Etwas schlankeres wäre mir doch lieber.
Grund genug sich einmal den smtp-Client von Postfix anzuschauen und mal herauszufinden, was das Ding in die Richtung alles kann. Grundsätzlich bin ich bei Postfix gewöhnt alles irgendwie über Dictionaries umzuschreiben und so Daten nahezu endlos umzubiegen. Ein gutes Beispiel wäre hier sicherlich die Struktur unserer Relay-Funktionalität, die sich auch auf einzelne E-Mail-Adressen beschränken lässt und sich Domains so im gemischten Betrieb verwalten lassen. Oder natürlich auch die Anbindung von Zarafa-Mailboxen im Multi-Tenancy- sowie gemischten Betrieb mit normalen POP3/IMAP-Mailboxen - aber ich schweife ab.
Der SMTP-Client von Postfix kennt mit den smtp_generic_maps tatsächlich auch ein Dictionary um den Absender einer E-Mail umzuschreiben, also eigentlich wäre hier genau der richtige Punkt um mit einer SRS-Implementation anzusetzen. Ein einziges Problem gibt es dann allerdings:
Die smtp_generic_maps kommen sowohl für den Absender wie auch den Empfänger zum Einsatz und man kann technisch bedingt nicht unterscheiden, wonach genau gerade gesucht wird.
Die Lösung des Problems ist daher ganz einfach: Die smtp_generic_maps auseinander friemeln. Genau das tut ein Postfix-Patch (für 2.8 Patchlevel 1) von uns, den ich just in unser Build-System geschickt habe: Neben den smtp_generic_maps führt der Patch die smtp_sender_maps ein, die nur für MAIL FROM:-Einträge konsultiert werden.
Fehlt eigentlich nur noch das passende Dictionary, dass die Verarbeitung bzw. Konvertierung der Absender-Adressen vornimmt. Für den Moment behalte ich näheres dazu aber für mich bzw. überlasse das gerne der Community, zumal wir da noch nichts produktives haben - unsere SRS-Bibliothek hat noch Probleme mit SRS1 nach SRS1. Mal davon abgesehen, dass der Weg zurück noch gar nicht gebaut ist
Dienstag, 8. März 2011
Zarafa und Z-Push in FastCGI-Umgebung
Montag, 7. März 2011
Autokonfiguration für Mozilla Thunderbird
Wir bieten seit heute morgen eine gewisse Unterstützung für die Autokonfiguration von Mozilla Thunderbird.
So ganz glücklich bin ich mit dem Status Quo nicht, er mutet an zwei Stellen etwas dreckig an, ist aber definitiv schöner als der Zustand vorher. Zum einen haben wir uns auf den E-Mail-Domains die Subdomain "autoconfig.%DOMAIN" genommen bzw. nehmen müssen.
Eine Delegation der Einstellungen über DNS wäre da wesentlich schöner gewesen und das Thunderbird-Projekt hat da auch schon was in der Mache - funktionieren tut es nur noch nicht 
Ein weiterer Nachteil ist, dass sich bei uns der Benutzername von der E-Mail-Adresse unterscheidet oder - anders gesagt - ein Benutzer mehrere E-Mail-Adressen haben kann, die er über die selbe Mailbox abholt. Thunderbird ist sich dieses Umstand bewusst hat aber noch keine Lösung parat, die "stable" wäre. Schlussendlich müssen wir da wohl noch etwas warten - bis dahin schlagen wir als Benutzernamen "BEARBEITEN" vor - mit einem schönen "Bearbeiten"-Button daneben. Ich hoffe mal jeder ist so weise den auch zu klicken
Mittwoch, 23. Februar 2011
Wenn der Iterator sich komisch verhält
Ein wenig naiv war ich gestern in meinem logischen Denken irgendwie schon. Aber was war überhaupt passiert?
Ich hatte mit PHP ein Objekt über ein Array gelegt und das Interface "Iterator" implementiert um mit einer foreach()-Schleife direkt an die Inhalte des Arrays ranzukommen. Später dann wunderte ich mich, dass ich in einer Schleife immer nur das erste Element aus dem Array geliefert bekam und die anderen stillschweigend verschwanden.
Eigentlich lag die Lösung immer schon direkt vor meiner Nase, denn schon vorher hatte ich mich gewundert, dass wenn ich während der Schleife das aktuelle Element aus dem Array entferne, das nächste übersprungen wird. Eigentlich ganz einfach: Der Zeiger der foreach()-Schleife bleibt an der gleichen Position, nur die Elemente rutschen beim Löschen von hinten nach. Dementsprechend sollte man ihn nach dem Löschen mittels prev() zurück bewegen, bevor die foreach()-Schleife ein next() triggert. Dementsprechend ahnte ich schon, dass es nicht so ganz einfach ist mit meinem Objekt das exakt selbe Verhalten eines klassischen Arrays nachzustellen.
Aber warum lieferte mir die genannte Schleife nur noch ein Element aus einem Array mit mehreren Elementen?
Recht einfach: Mein Array-Objekt hat genau einen Zeiger auf die aktuelle Position im Array. Verschachtelt man nun ein paar foreach()-Schleifen, so entsteht hier ein heilloses Chaos und das Ergebnis wird niemals das erwartete sein.
Die ernüchternde Lösung meines Problems war dann schlichtweg ein IteratorAggregate und somit das Kopieren des Arrays für jede foreach()-Schleife. Ich kann mir gerade Szenarien vorstellen, wo auch das vermutlich schief gehen würde, allerdings sind die mir noch gar nicht untergekommen und ich wüsste ehrlich gesagt auch gar nicht, wie sich da ein normales Array verhält.
Hauptsache es tut für den Moment
Freitag, 11. Februar 2011
Neues von der Skripte-Front
Eigentlich ist es ja schon recht lange her, das ich über ein paar Fortschritte bei unserer Python-Implementierung geschrieben habe. Das Projekt war auch zugegebenermaßen auch etwas ins Stocken geraten, da ein paar Aufgaben anstanden, die aus wirtschaftlicher Sicht interessanter waren.
Das ging soweit, dass ich zwischenzeitlich gar nicht mehr wusste, dass die Schnittstelle gar kein CGI mehr spricht, sondern auf WSGI umgestellt wurde. Auch war mir gar nicht mehr bewusst, dass wir schon erste Geh-Versuche mit Ruby als weitere Skripting-Sprache gemacht hatten. Irgendwie ist nun abder doch wieder leben in die Sache gekommen.
Letzte Woche habe ich aus beiden Projekten den FastCGI-Code herausgeschnitten und eine abstrahierte Schicht zwischen Webserver und Skripting-Sprache geschaffen, die insgesamt leichter zu warten und etwas performanter als ihr Vorgänger scheint. Sehr schön 
Das Problem, dass Kunden nicht beliebige Programme auf den Servern ausführen sollen, und ihnen auch der Blick in manche Verzeichnisse von vorne herein aus Prinzip verwehrt sein soll (vgl. PHP's open_basedir) ist auch schon angegangen worden - in Form einer lustigen kleinen Bibliothek, die einfach die (f)open's und exec's überlädt und entsprechend beschneidet.
Sowohl beim Überladen wie aber auch beim Abgreifen der Ausgabe eines Skriptes sei gesagt: Python arbeitet gerne mit fopen, d.h. man kann auch die Standard-Ausgabe jederzeit mit Cookies umleiten. Ruby hingegen greift auf das näher am Kernel liegende open zurück und holt sich von jedem FILE-Handle die entsprechende Deskriptor-Nummer. Wer hier eingreifen will muss tricksen - tut auch die abstrakte FastCGI-Schicht.
In beiden Fällen stehen eigentlich nur noch ein paar Tests bzgl. Performance und Ausfallsicherheit an. Viel schwieriger sind da aber dann andere Fragen, zum Beispiel werden Python-Skripte meistens per SSH installiert oder brauchen eine Shell - sowas bieten wir ja erst einmal konsequent nicht an. :-/
Freitag, 4. Februar 2011
Push-Dienst ActiveSync
Samstag, 15. Januar 2011
Jabber-Gespräche serverseitig mitschneiden
In der Diskussionsrunde nach meinem Vortrag am Donnerstag wurde unter anderem nochmal der Wunsch nach einem serverseitigen Gesprächsverlauf um nicht bei einem Wechsel des Clients oder Gerätes zerschnittene Protokolle zu haben.
Nun gibt es bereits XMPP-Dienste, die sowas über eine eigene Oberfläche ermöglichen, es stellt sich aber immer die Frage, ob man will dass die Betreiber der selbigen (offiziell? ) die eigenen Konversationen mitloggen. Der interessierte Geek wird sowieso lieber selber loggen wollen bevor er irgendwem anderes die Macht über seine Daten gibt.
Mir ist das Thema im Kopf geblieben und ich als Geek wollte in dem Fall einfach nur mal spielen.
Heraus gekommen ist dabei eine Jabberd2-Komponente, die sich als "logging sink" am Server anmeldet und Konversationen ganz stupide auf die Festplatte schreibt - natürlich nur sofern dies auch gewünscht wird. Andernfalls wird alles bedingungslos verworfen.
"Gewünscht werden" ist in diesem Fall recht simpel: Der Dienst stellt fest, wem eine Nachricht gehört ("owner") und wer sein Gegenüber ist ("opponent") und schaut nach ob ein Verzeichnis "history/owner/" existiert - wenn dem so ist, wird gelogged.
Die viel spannendere Frage ist dann aber eher, wie man an die Mitschnitte seiner Gespräche kommt. Zwar existiert mit dem XEP-0136 bereits ein Entwurf zum Archivieren von Nachrichten, allerdings ist es wie erwähnt im Monent lediglich ein Entwurf, kaum ein Client unterstützt die Erweiterung und es wird explizit darauf hingewiesen, dass dieser Ansatz noch zu überarbeiten ist. Schade!
Ich habe mich folglich für einen Mix aus Service Discovery (XEP-0030), Ad-Hoc Commands (XEP-0050) und Delayed Delivery (XEP-0203) entschieden und auch über In-Band Registration (XEP-0077) nachgedacht. In der Summe ist es nicht wirklich schön geworden, aber es funktioniert.
Gerade wenn man sich den Teil bestehend aus Service Discovery und Ad-Hoc Commands anschaut und das "Replay" von Gesprächen mal außen vor lässt ist es eigentlich noch schön anzugucken:
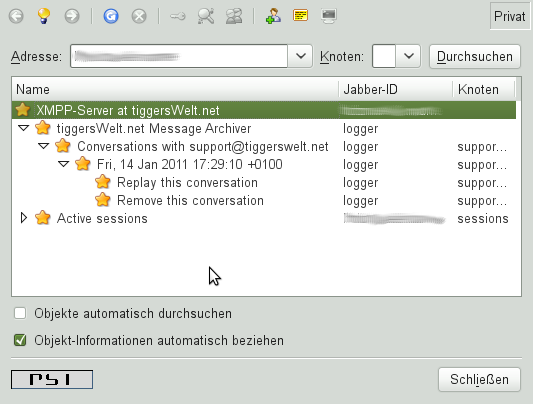
Der Dienst erscheint als Service unterhalb der eigenen Domain. Sofern bereits Gesprächspartner existieren, werden diese nach Jabber-ID sortiert direkt als Knoten unterhalb des Dienstes angezeigt. Unterhalb dieses Knotens findet man dann die Gespräche nach Datum sortiert.
Mit den Ad-Hoc Commands kann man die Protokolle dann nochmal lesen oder direkt vom Server löschen lassen. Wobei ersteres irgendwie noch Ekelhaft ist:
Der Dienst (in diesem Fall "logger") schickt Chat-Nachrichten an den Eigentümer der Konversation und stellt die jeweilige Jabber-ID des ursprünglichen Absenders voran. Delayed Delivery hilft dabei den ursprünglichen Absender und Zeitstempel mit zu übertragen - letzteres wird aber längst nicht von jedem unterstützt und hat gerade beim "ursprünglichen Absender" immer irgendwo ein Geschmäckle.
Der Dienst ist keine propietäre Erweiterung, die ich bei mir in der Schublade verschwinden lassen würde. Im Gegenteil:
Er befindet sich in den Code-Beispielen meiner XMPP-Library, da es eigentlich nur ein Interface für die Logging-Sink-Variante der Jabberd2-Komponente ist - somit Open-Source und für jedermann nutzbar. Wenn man denn will.
Anders herum weiß ich gar nicht, ob ich so eine Komponente im produktiven Einsatz haben möchte. Wenn man sich ein Webinterface dazu denkt, eigentlich ne super Sache, aber son bisschen Geschmack nach Stasi & Co. hab ich dann schon im Mund.
Vielleicht wartet man hier einfach besser bis das Message Archiving (XEP-0136) als Standard abgesegnet wird, da wird dann ja auch geregelt wie der Nutzer über eine etwaige Protokollierung seiner Unterhaltungen zu informieren ist. Bis dahin sei sowieso jedem GnuPG oder OTR ans Herz gelegt.
Donnerstag, 13. Januar 2011
CCCS-Vortrag: IRC trifft Jabber/XMPP
Montag, 27. Dezember 2010
OpenVPN und MTU 1500
Suche
Read this blog!
Kategorien
Blog abonnieren

Buttons
![]()
![]()
Kommentare